2.1 TextRank算法理论基础
TextRank算法介绍
学习目标
- 理解TextRank算法的来源.
- 掌握TextRank算法的概念.
- 掌握TextRank算法的代码实践.
TextRank算法的来源
- 在介绍TextRank算法之前, 我们先来简单回顾一下著名的PageRank算法.
- PageRank算法: 通过计算网页链接的数量和质量来评估网页的重要性, 算法发明人即谷歌的两位联合创始人之一的拉里.佩奇(Larry Page). 最初被应用在搜索引擎优化操作中.
- 联想思维: PageRank算法其实是借鉴了学术界评价学术论文重要性的通用方法-“影响因子”, 可以直观的理解为”该论文被引用的次数”.
这样就可以很自然的得到PageRank的核心思想:
如果一个网页被很多其他网页连接到的话, 说明这个网页比较重要, 也就是PageRank值会比较高.
如果一个PageRank值很高的网页链接到另一个网页, 那么被链接到的那个网页的PageRank值也会相应的被提高.
PageRank算法简介:
图 1 PageRank算法
假设我们有4个网页——w1,w2,w3,w4。这些页面包含指向彼此的链接。有些页面可能没有链接,这些页面被称为悬空页面。
- w1有指向w2、w4的链接
- w2有指向w3和w1的链接
- w4仅指向w1
- w3没有指向的链接,因此为悬空页面
为了对这些页面进行排名,我们必须计算一个称为PageRank的分数。这个分数是用户访问该页面的概率。
为了获得用户从一个页面跳转到另一个页面的概率,我们将创建一个正方形矩阵M,它有n行和n列,其中n是网页的数量。
矩阵中得每个元素表示从一个页面链接进另一个页面的可能性。比如,如下高亮的方格包含的是从w1跳转到w2的概率。
如下是概率初始化的步骤:
- 从页面i连接到页面j的概率,也就是M[i][j],初始化为1/页面i的出链接总数wi
- 如果页面i没有到页面j的链接,那么M[i][j]初始化为0
- 如果一个页面是悬空页面,那么假设它链接到其他页面的概率为等可能的,因此M[i][j]初始化为1/页面总数
因此在本例中,矩阵M初始化后如下:
最后,这个矩阵中的值将以迭代的方式更新,以获得网页排名。
TextRank算法的概念
现在我们已经掌握了PageRank,让我们理解TextRank算法。我列举了以下两种算法的相似之处:
- 用句子代替网页
- 任意两个句子的相似性等价于网页转换概率
- 相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
TextRank算法是一种抽取式的无监督的文本摘要方法。让我们看一下我们将遵循的TextRank算法的流程:
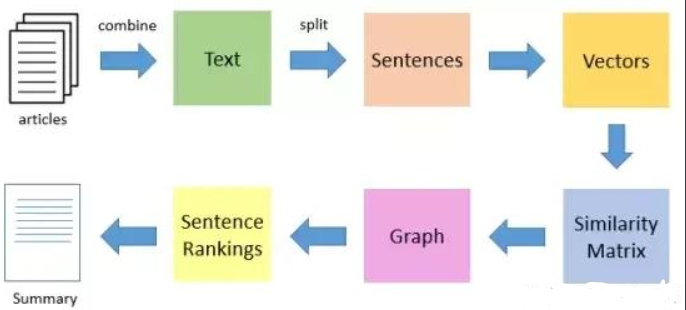
- 第一步是把所有文章整合成文本数据
- 接下来把文本分割成单个句子
- 然后,我们将为每个句子找到向量表示(词向量)
- 计算句子向量间的相似性并存放在矩阵中
- 然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算。
- 最后,一定数量的排名最高的句子构成最后的摘要
- 对比于衡量网页重要性的PageRank算法, TextRank算法用于衡量哪些单词是关键词, 类比之下的算法思想也就很好理解了:
- 如果一个单词出现在很多单词的后面, 就是它和很多单词有关联, 那么说明这个单词比较重要.
- 如果一个TextRank值很高的单词后面跟着另一个单词, 那么后面这个单词的TextRank值也会相应的被提高.
- TestRank属于抽取型摘要
- 如果对TextRank更深的理论感兴趣, 可以直接查询原始论文, 地址如下:
TextRank算法代码实践
- 在本小节中, 展示如何具体在代码层面用TextRank.
- 关键词抽取(keyword extraction)
- 关键短语抽取(keyphrase extraction)
- 关键句抽取(sentence extraction)
关键词抽取(keyword extraction)
- 关键词抽取: 是指从文本中确定一些能够描述文档含义的关键术语的过程.
- 对关键词抽取而言, 用于构建顶点集的文本单元可以使句子中的一个或多个字. 根据这些字之间的关系构建边.
- 根据任务的需要, 可以使用语法过滤器(syntactic filters)对顶点集进行优化. 语法过滤器的主要作用是将某一类或者某几类词性的字过滤出来作为顶点集.
- 在真实的企业场景下, 应用TextRank一般都直接采用基于textrank4zh工具包来说辅助工程.
# coding=utf-8
# 导入textrank4zh的相关工具包
from textrank4zh import TextRank4Keyword, TextRank4Sentence
# 导入常用工具包
import pandas as pd
import numpy as np
#关键词抽取
def keywords_extraction(text):
# allow_speech_tags : 词性列表, 用于过滤某些词性的词
tr4w = TextRank4Keyword(allow_speech_tags=['n', 'nr', 'nrfg', 'ns', 'nt', 'nz'])
# text: 文本内容, 字符串
# window: 窗口大小, int, 用来构造单词之间的边, 默认值为2
# lower: 是否将英文文本转换为小写, 默认值为False
# vertex_source: 选择使用words_no_filter, words_no_stop_words, words_all_filters中的>哪一个来构造pagerank对应的图中的节点
# 默认值为'all_filters', 可选值为'no_filter', 'no_stop_words', 'all_filters'
# edge_source: 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来构造pagerank对应的图中的节点之间的边
# 默认值为'no_stop_words', 可选值为'no_filter', 'no_stop_words', 'all_filters', 边的构造要结合window参数
# pagerank_config: pagerank算法参数配置, 阻尼系数为0.85
tr4w.analyze(text=text, window=2, lower=True, vertex_source='all_filters',
edge_source='no_stop_words', pagerank_config={'alpha': 0.85, })
# num: 返回关键词数量
# word_min_len: 词的最小长度, 默认值为1
keywords = tr4w.get_keywords(num=6, word_min_len=2)
# 返回关键词
return keywords- 调用:
if __name__ == "__main__":
text = "来源:中国科学报本报讯(记者肖洁)又有一位中国科学家喜获小行星命名殊荣!4月19日下午,中国科学院国家天文台在京举行“周又元星”颁授仪式," \
"我国天文学家、中国科学院院士周又元的弟子与后辈在欢声笑语中济济一堂。国家天文台党委书记、" \
"副台长赵刚在致辞一开始更是送上白居易的诗句:“令公桃李满天下,何须堂前更种花。”" \
"据介绍,这颗小行星由国家天文台施密特CCD小行星项目组于1997年9月26日发现于兴隆观测站," \
"获得国际永久编号第120730号。2018年9月25日,经国家天文台申报," \
"国际天文学联合会小天体联合会小天体命名委员会批准,国际天文学联合会《小行星通报》通知国际社会," \
"正式将该小行星命名为“周又元星”。"
#关键词抽取
keywords=keywords_extraction(text)
print(keywords)- 输出结果:
[{'word': '小行星', 'weight': 0.05808441467341854},
{'word': '天文台', 'weight': 0.05721653775742513},
{'word': '命名', 'weight': 0.0485177005159723},
{'word': '中国', 'weight': 0.045716478124251815},
{'word': '中国科学院', 'weight': 0.037818937836996636},
{'word': '国家', 'weight': 0.03438059254484016}]关键短语抽取(keyphrase extraction)
- 关键短语抽取: 关键词抽取结束后, 可以得到N个关键词, 在原始文本中相邻的关键词便构成了关键短语.
- 具体方法: 分析get_keyphrases()函数可知, 内部实现上先调用get_keywords()得到关键词, 然后分析关键词是否存在相邻的情况, 最后即可确定哪些是关键短语.
from textrank4zh import TextRank4Keyword, TextRank4Sentence
#关键短语抽取
def keyphrases_extraction(text):
tr4w = TextRank4Keyword()
tr4w.analyze(text=text, window=2, lower=True, vertex_source='all_filters',
edge_source='no_stop_words', pagerank_config={'alpha': 0.85, })
# keywords_num: 抽取的关键词数量
# min_occur_num: 关键短语在文中的最少出现次数
keyphrases = tr4w.get_keyphrases(keywords_num=6, min_occur_num=1)
# 返回关键短语
return keyphrases- 调用:
if __name__ == "__main__":
text = "来源:中国科学报本报讯(记者肖洁)又有一位中国科学家喜获小行星命名殊荣!4月19日下午,中国科学院国家天文台在京举行“周又元星”颁授仪式," \
"我国天文学家、中国科学院院士周又元的弟子与后辈在欢声笑语中济济一堂。国家天文台党委书记、" \
"副台长赵刚在致辞一开始更是送上白居易的诗句:“令公桃李满天下,何须堂前更种花。”" \
"据介绍,这颗小行星由国家天文台施密特CCD小行星项目组于1997年9月26日发现于兴隆观测站," \
"获得国际永久编号第120730号。2018年9月25日,经国家天文台申报," \
"国际天文学联合会小天体联合会小天体命名委员会批准,国际天文学联合会《小行星通报》通知国际社会," \
"正式将该小行星命名为“周又元星”。"
#关键短语抽取
keyphrases=keyphrases_extraction(text)
print(keyphrases)- 输出结果:
['小行星命名']关键句抽取(sentence extraction)
- 关键句抽取: 句子抽取任务主要就是为了解决自动文本摘要任务, 将每一个sentence作为一个顶点, 根据两个句子之间的内容重复程度来计算他们之间的相似度. 由于不同的句子对之间相似度大小不同, 因此最终构建的是以相似度大小作为edge权重的有权图.
- 代码实现中, 可以直接调用函数完成:
from textrank4zh import TextRank4Keyword, TextRank4Sentence
#关键句抽取
def keysentences_extraction(text):
tr4s = TextRank4Sentence()
# text: 文本内容, 字符串
# lower: 是否将英文文本转换为小写, 默认值为False
# source: 选择使用words_no_filter, words_no_stop_words, words_all_filters中的哪一个来生成句子之间的相似度
# 默认值为'all_filters', 可选值为'no_filter', 'no_stop_words', 'all_filters'
tr4s.analyze(text, lower=True, source='all_filters')
# 获取最重要的num个长度大于等于sentence_min_len的句子用来生成摘要
keysentences = tr4s.get_key_sentences(num=3, sentence_min_len=6)
# 返回关键句子
return keysentences- 调用:
if __name__ == "__main__":
text = "来源:中国科学报本报讯(记者肖洁)又有一位中国科学家喜获小行星命名殊荣!4月19日下午,中国科学院国家天文台在京举行“周又元星”颁授仪式," \
"我国天文学家、中国科学院院士周又元的弟子与后辈在欢声笑语中济济一堂。国家天文台党委书记、" \
"副台长赵刚在致辞一开始更是送上白居易的诗句:“令公桃李满天下,何须堂前更种花。”" \
"据介绍,这颗小行星由国家天文台施密特CCD小行星项目组于1997年9月26日发现于兴隆观测站," \
"获得国际永久编号第120730号。2018年9月25日,经国家天文台申报," \
"国际天文学联合会小天体联合会小天体命名委员会批准,国际天文学联合会《小行星通报》通知国际社会," \
"正式将该小行星命名为“周又元星”。"
#关键句抽取
keysentences=keysentences_extraction(text)
print(keysentences)- 输出结果:
[{'index': 4, 'sentence': '2018年9月25日,经国家天文台申报,国际天文学联合会小天体联合会小天体命名委员会批准,国际天文学联合会《小行星通报》通知国际社会,正式将该小行星命名为“周又元星”', 'weight': 0.2281040325096452},
{'index': 3, 'sentence': '”据介绍,这颗小行星由国家天文台施密特CCD小行星项目组于1997年9月26日发现于兴隆观测站,获得国际永久编号第120730号', 'weight': 0.2106246105971721},
{'index': 1, 'sentence': '4月19日下午,中国科学院国家天文台在京举行“周又元星”颁授仪式,我国天文学家、中国科学院院士周又元的弟子与后辈在欢声笑语中济济一堂', 'weight': 0.2020923401661083}]基于jieba的TextRank算法
- jieba工具不仅仅可以用来分词, 进行词性分析. 也可以用来完成TextRank.
import jieba.analyse
def jieba_keywords_textrank(text):
keywords = jieba.analyse.textrank(text, topK=6)
return keywords- 调用:
if __name__ == "__main__":
text = "来源:中国科学报本报讯(记者肖洁)又有一位中国科学家喜获小行星命名殊荣!4月19日下午,中国科学院国家天文台在京举行“周又元星”颁授仪式," \
"我国天文学家、中国科学院院士周又元的弟子与后辈在欢声笑语中济济一堂。国家天文台党委书记、" \
"副台长赵刚在致辞一开始更是送上白居易的诗句:“令公桃李满天下,何须堂前更种花。”" \
"据介绍,这颗小行星由国家天文台施密特CCD小行星项目组于1997年9月26日发现于兴隆观测站," \
"获得国际永久编号第120730号。2018年9月25日,经国家天文台申报," \
"国际天文学联合会小天体联合会小天体命名委员会批准,国际天文学联合会《小行星通报》通知国际社会," \
"正式将该小行星命名为“周又元星”。"
# 基于jieba的textrank算法实现
keywords = jieba_keywords_textrank(text)
print(keywords)- 输出结果:
['小行星', '命名', '国际', '中国', '国家', '天文学家']


