机器学习
一,机器学习的任务
- 这里的任务主要指监督学习
分类任务
回归任务
多标签分类(更加前沿)
1.分类任务
二分类(垃圾邮件判断)
多分类(数字识别,图像识别,用户客户信用卡风险评级判断)
很多复杂的问题也可以转换成多分类问题(智能驾驶,下围棋)
概要
- 一些算法只支持完成二分类的任务
- 多分类任务可以转换成二分类任务
- 一些算法天然可以完成多分类任务
2.回归任务(房屋价格,市场分析,学生成绩)
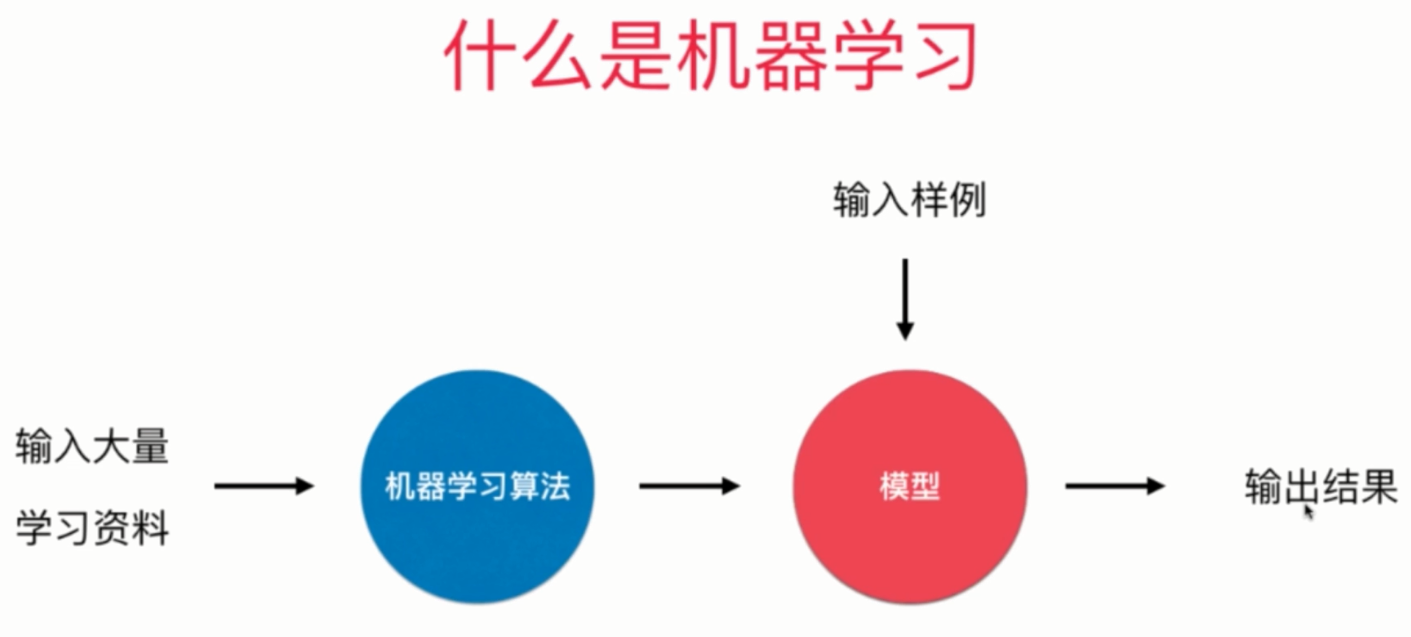
二,机器学习方法的分类
监督学习
非监督学习
半监督学习
增强学习
1. 监督学习
- 给机器的训练数据集是带有标签的数据,主要任务包括分类任务和回归任务
k近邻
线性回归和多项式回归
逻辑回归
SVM
决策树和随机森林
2.非监督学习
- 给机器的训练数据没有任何“标记”或者“答案”
- 对没有“标记”的数据进行分类-聚类分析
- 还可对数据进行降维处理
- 特征提取:信用卡的信用评级和人的胖瘦无关?
- 特征压缩:PCA,高维的特征向量压缩到低维的特征向量
3.半监督学习
- 一部分数据有“标记”或者“答案”,另一部分数据没有
- 更常见的是:各种原因产生的标记缺失
4.增强学习
- 根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式
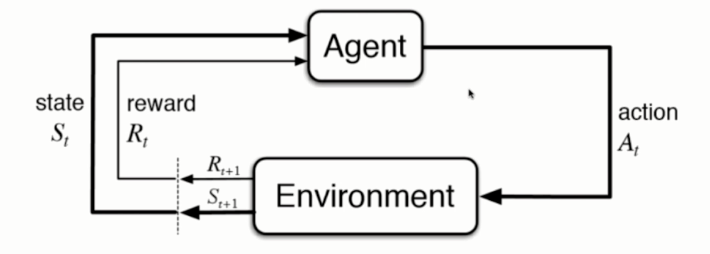
- 适合机器人的学习机制
三,机器学习的其他分类
在线学习和批量学习(离线学习)
参数学习和非参数学习
1.批量学习
- 无法进行增量学习。先训练全数据集,得到训练后的模型,在实际应用中,将数据输入到模型中,得到输出。如果更新训练样本集,需要重新训练模型。
- 优点:简单
- 问题:如何适应环境变化?
- 解决方案:定时重新批量学习
- 缺点:每次重新批量学习,运算量巨大;在某些环境变化非常大的情况下,甚至不可能的。
2.在线学习
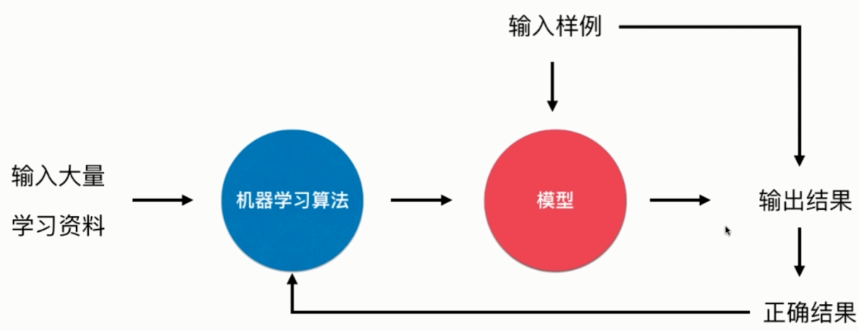
优点:及时反应新的环境变化
问题:新的数据带来不好的变化?
- 解决方案:需要加强对数据进行监控
其他:也适用于数据量巨大,完全无法批量学习的环境
3.参数学习
- 一旦学到了参数,就不在需要以前的数据集
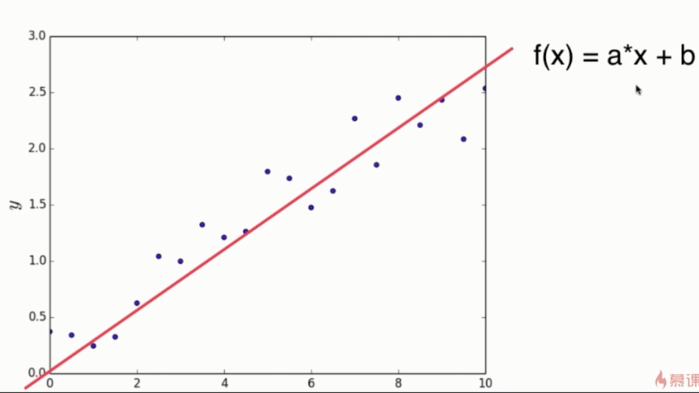
即学习参数a和b
4.非参数学习
- 不对模型进行过多的假设
- 非参数不等于没有参数



