BERT
1. 简介
全称BERT 全名为 Bidirectional Encoder Representations from Transformers,是 Google 以无监督的方式利用大量无标注文本训练的语言代表模型,其框架主要组成本分为 Transformer 中的 Encoder。如图蓝色框所示。
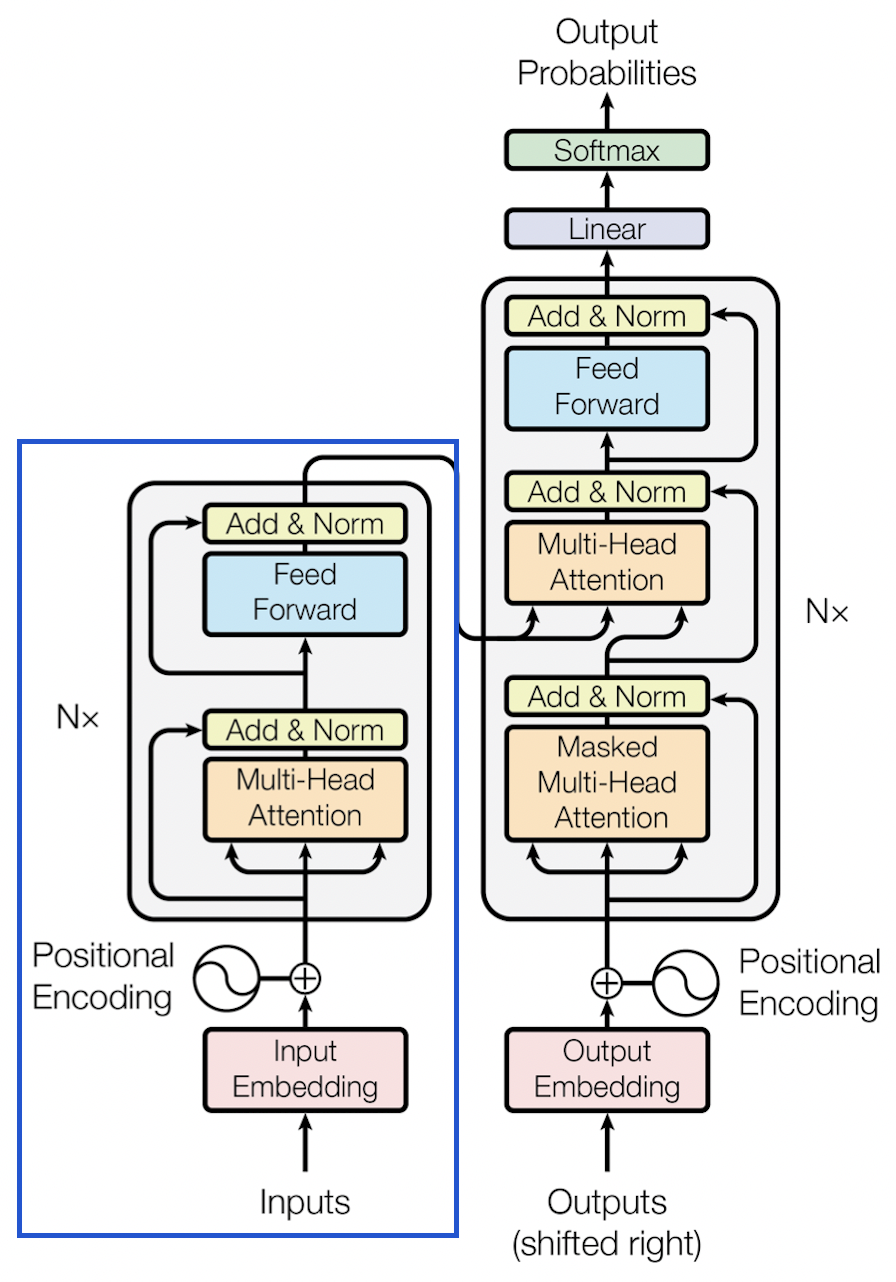
BERT是传统语言模型的变形,语言模型(language Model,LM)就是在给定一个单词的前提下去估计下一个单词出现的概率分布,LSTM也是一种语言模型,只是差了BERT很多数量级。

训练一个LM的好处:
- 无监督数据无限大,网络上的所有文本都可以成为潜在的训练数据(BERT预训练的数据集有33亿字)。
- 好的语言模型甚至可以学会语法结构甚至指代消解,通过特征迁移或者fine-tuning更好的训练下游任务并提升其表现。
- 减少不同NLP任务中所需的 architecture engineering成本。
第1,2点意义容易让人理解,但是第3点的意义也十分深远,对于不同的NLP任务设计不同的神经网络模型并测试其表现是十分耗费成本的, BERT 就是一个可以直接用于处理各式NLP任务的通用性框架。BERT 论文的作者们使用 Transfomer Encoder、大量文本以及两个预训练目标,事先训练好一個可以套用到多個 NLP 任务的 BERT 模型,再以此为基础 fine tune 多个下游任务。
这就是近来NLP领域非常流行的两阶段迁移学习:
- 先以 LM Pretraining 的方式预先训练出一個对自然语言有一定「理解」的通用模型。
- 再将该模型拿来做特征迁移或是 fine tune 下游的(监督式)任务。
坏消息是BERT的训练基本无法复现,要训练好一个有 1.1 亿参数的 12 层 BERT-BASE 得用 16 个 TPU chips 跑上整整 4 天,花費 500 鎂。实际情况下多次实验要乘上几倍。
2.BERT的主要预训练任务
谷歌在训练BERT时让它同时进行两个任务:
任务一: Masked LM (带mask的语言模型训练)
- 关于传统的语言模型训练, 都是采用left-to-right, 或者left-to-right + right-to-left结合的方式, 但这种单向方式或者拼接的方式提取特征的能力有限. 为此BERT提出一个深度双向表达模型(deep bidirectional representation). 即采用MASK任务来训练模型.
- 1: 在原始训练文本中, 随机的抽取15%的token作为参与MASK任务的对象.
- 2: 在这些被选中的token中, 数据生成器并不是把它们全部变成[MASK], 而是有下列3种情况.
- 2.1: 在80%的概率下, 用[MASK]标记替换该token, 比如my dog is hairy -> my dog is [MASK]
- 2.2: 在10%的概率下, 用一个随机的单词替换token, 比如my dog is hairy -> my dog is apple
- 2.3: 在10%的概率下, 保持该token不变, 比如my dog is hairy -> my dog is hairy
- 3: 模型在训练的过程中, 并不知道它将要预测哪些单词? 哪些单词是原始的样子? 哪些单词被遮掩成了[MASK]? 哪些单词被替换成了其他单词? 正是在这样一种高度不确定的情况下, 反倒逼着模型快速学习该token的分布式上下文的语义, 尽最大努力学习原始语言说话的样子. 同时因为原始文本中只有15%的token参与了MASK操作, 并不会破坏原语言的表达能力和语言规则.
任务二: Next Sentence Prediction (下一句话预测任务)
- 在NLP中有一类重要的问题比如QA(Quention-Answer), NLI(Natural Language Inference), 需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任务. 在BERT中引入的就是Next Sentence Prediction任务. 采用的方式是输入句子对(A, B), 模型来预测句子B是不是句子A的真实的下一句话.
- 1: 所有参与任务训练的语句都被选中作为句子A.
- 1.1: 其中50%的B是原始文本中真实跟随A的下一句话. (标记为IsNext, 代表正样本)
- 1.2: 其中50%的B是原始文本中随机抽取的一句话. (标记为NotNext, 代表负样本)
- 2: 在任务二中, BERT模型可以在测试集上取得97%-98%的准确率.
3.BERT的网络结构
3.1 总体框架
3.1.1 输入部分
- 如下图所示, 最左边的就是BERT的架构图, 可以很清楚的看到BERT采用了Transformer Encoder block进行连接, 因为是一个典型的双向编码模型,多头自注意力中的每个头的输入都同时蕴含了前后文的语言信息。
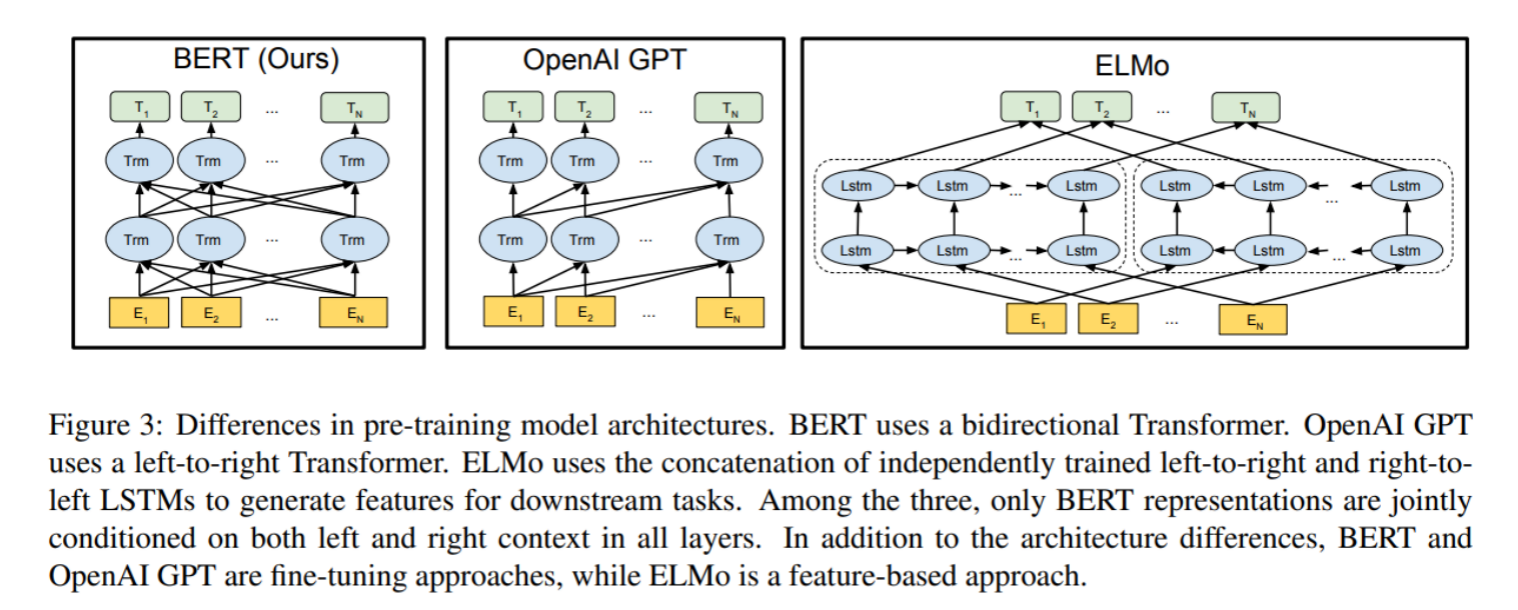
- 从上面的架构图中可以看到, 宏观上BERT分三个主要模块.
- 最底层黄色标记的Embedding模块。
- 中间层蓝色标记的Transformer模块。
- 最上层绿色标记的预微调模块。
Embedding模块: BERT中的该模块是由三种Embedding共同组成而成, 如下图
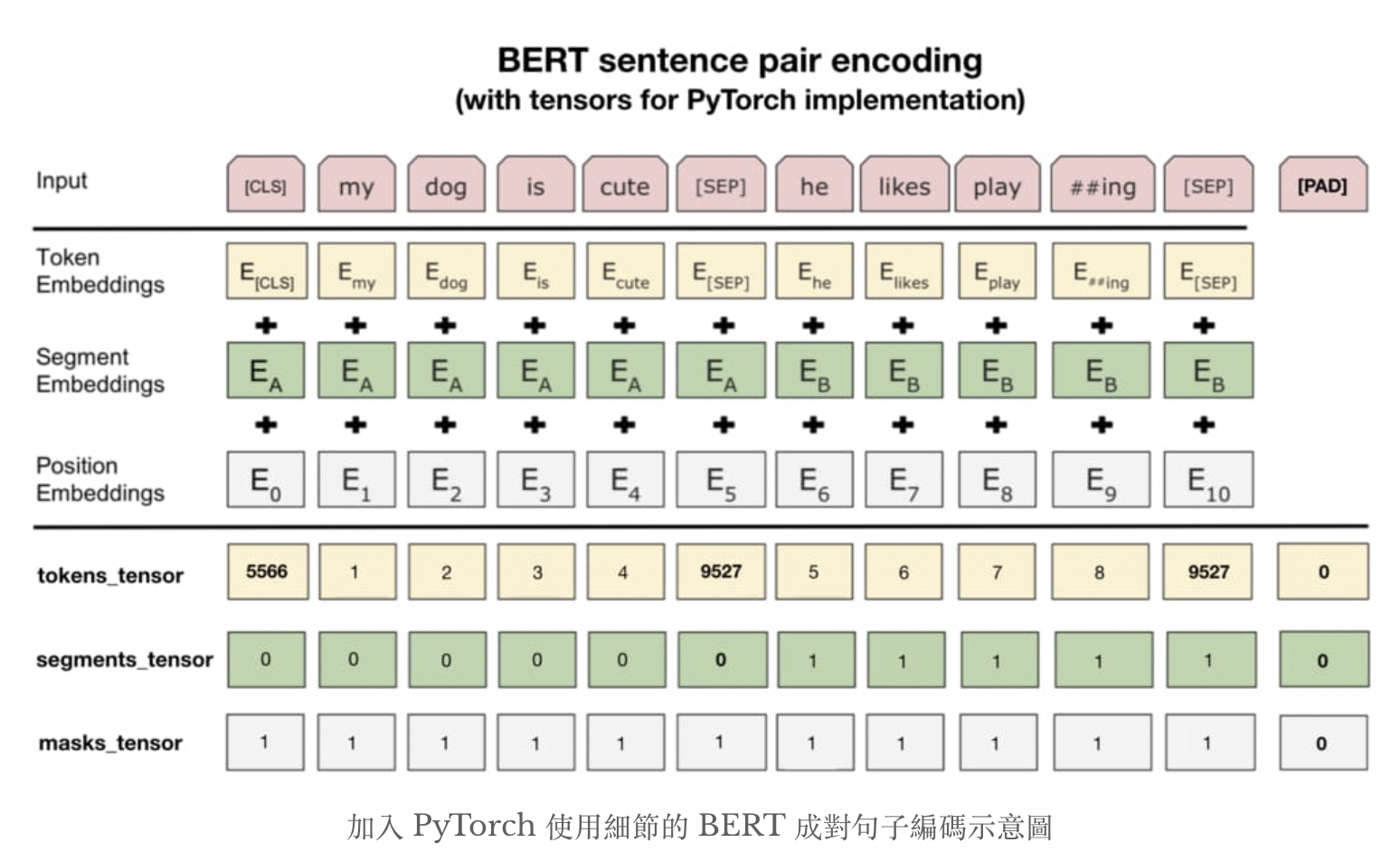
第二条分割线上是BERT论文中展示的例子。图中Token Embedding都对应到前面提到的wordpiece,Segment Embedding代表不同句子的位置,Positional Embedding则类似于Transformer架构中的位置编码器。
在实际运用中最重要的是第二条分割线下面的操作,需要将原始文本转换成3种id tensor:
- token_tensor:每个token对应的索引值。
- Segments_tensor:用来识别句子界限,第一句为0,第二句为1,句子间的[SEP]为0。
- Masks_tensor:用来界定自注意力机制范围。1让BERT关注该位置,0则代表padding不需要关注。
3.1.2 内部网路结构
BERT提供了简单和复杂两个模型,对应的超参数分别如下:
- BERT-base : L=12,H=768,A=12,参数总量110M;
- BERT-large: L=24,H=1024,A=16,参数总量340M;
在上面的超参数中,L表示网络的层数(即Transformer blocks的数量),A表示Multi-Head Attention中self-Attention的数量,filter的尺寸是4H。
4.模型代码测试
4.1 安装相关包
# Python 3.6.13
# torch版本
>>> import torch
>>> torch.__version__
'1.9.0'
# 安装包
pip install transformers pytorch_transformers tqdm boto3 requests regex -q4.2 载入中文BERT使用的tokenizer
Hugging Face 团队的 repo 里看到所有可从 PyTorch Hub 載入的 BERT 预训练模型。截至目前为止有以下模型可供使用,本例中使用bert-base-chinese
- bert-base-chinese
- bert-base-uncased
- bert-base-cased
- bert-base-german-cased
- bert-base-multilingual-uncased
- bert-base-multilingual-cased
- bert-large-cased
- bert-large-uncased
- bert-large-uncased-whole-word-masking
- bert-large-cased-whole-word-masking
import torch
# from transformers import BertTokenizer, BertConfig
from pytorch_transformers import *
from annoy import AnnoyIndex
# bert模型路径
MODEL_PATH = "./bert-base-chinese"
# 通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(MODEL_PATH)
# 查看tokenizer中的词典长度
len = tokenizer.vocab_size
print("词表长度", len)
# 词表长度 21128
# 查看字典内容
vocab = tokenizer.vocab
# 随机查看BERT字典中一些tokens以及对应的索引
random_tokens = random.sample(list(vocab), 10)
random_ids = [vocab[t] for t in random_tokens]
print("{0:20}{1:15}".format("token", "index"))
print("-" * 25)
for t, id in zip(random_tokens, random_ids):
print("{0:15}{1:10}".format(t, id))
# token index
# -------------------------
# 濱 4097
# ##ame 10816
# 訕 6247
# ##ube 10957
# コメント 12167
# ios 8276
# ##泌 16846
# ##楽 16575
# ##葫 18929
# 12345678910 9363BERT使用使用的是WordPiece Tokenization,将words拆分成更小的wordpieces,有效处理不在字典里的词。中文大致上就是character-level tokenization,而有**##**前缀的tokens即为wordpiece。wordpieces 可以由收集大量文本找出其中常见的 pattern。
例如ㄅㄆㄇㄈ也有被收录:
indices = list(range(647, 657))
some_pairs = [(t, idx) for t, idx in vocab.items() if idx in indices]
for pair in some_pairs:
print(pair)
#('ㄅ', 647)
#('ㄆ', 648)
#('ㄇ', 649)
#('ㄉ', 650)
#('ㄋ', 651)
#('ㄌ', 652)
#('ㄍ', 653)
#('ㄎ', 654)
#('ㄏ', 655)
#('ㄒ', 656)利用BERT的tokenizer对中文句子进行分词
text = "[CLS] 等爱 [MASK] 了,就知道谁是真爱。"
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(text)
print(tokens[:10], '...')
print(ids[:10], '...')输出
[CLS] 等爱 [MASK] 了,就知道谁是真爱。
['[CLS]', '等', '爱', '[MASK]', '了', ',', '就', '知', '道', '谁'] ...
[101, 5023, 4263, 103, 749, 8024, 2218, 4761, 6887, 6443] ...- 除了常见的wordpiecs之外,还有5个特殊tokens:
[CLS] 分类任务中最后一层的句向量(1,768),可以看作整个输入序列的代表向量。
[SEP] 两个句子串接成一个句子输入序列,两个句子间插入该token以做分隔。
[UNK] 未出现在bert字典中的字用token取代。
[PAD] zero padding,对长度不一的句子进行补齐,方便进行batch运算。
[MASK] 未知遮罩,仅在模型训练时会用到。
4.3 Masked LM (带mask的语言模型训练)测试
def get_bert_mask_vec(content, index, num):
'''
打印填充mask后的语句
:param content: 文本内容
:param index: mask对应的index
:param num: 显示的预测个数
:return:
'''
tokens = tokenizer.tokenize(content)
ids = tokenizer.convert_tokens_to_ids(tokens)
token_tensor = torch.tensor([ids])
segments_tensors = torch.zeros_like(token_tensor)
maskedLM_model = BertForMaskedLM.from_pretrained(MODEL_PATH)
# 使用 masked LM 估計 [MASK] 位置所代表的實際 token
maskedLM_model.eval()
with torch.no_grad():
outputs = maskedLM_model(token_tensor, segments_tensors)
predictions = outputs[0]
del maskedLM_model
# 將 [MASK] 位置的機率分佈取 top k 最有可能的 tokens 出來
masked_index = index
k = num
probs, indices = torch.topk(torch.softmax(predictions[0, masked_index], -1), k)
predicted_tokens = tokenizer.convert_ids_to_tokens(indices.tolist())
# 显示topk可能的字,一般我们就取top1当作预测值
print("輸入 tokens :", tokens[:10], '...')
print('-' * 50)
for i, (t, p) in enumerate(zip(predicted_tokens, probs), 1):
tokens[masked_index] = t
print("Top {} ({:2}%):{}".format(i, int(p.item() * 100), tokens[:10]), '...')调用
text = "[CLS] 等到潮水 [MASK] 了,就知道誰沒穿褲子。"
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(text)
print(tokens[:10], '...')
print(ids[:10], '...')
# token_tensor = torch.tensor([ids])
# segments_tensors = torch.zeros_like(token_tensor)
get_bert_mask_vec(text, index=5, num=10)输出
輸入 tokens : ['[CLS]', '等', '到', '潮', '水', '[MASK]', '了', ',', '就', '知'] ...
--------------------------------------------------
Top 1 (67%):['[CLS]', '等', '到', '潮', '水', '來', '了', ',', '就', '知'] ...
Top 2 (25%):['[CLS]', '等', '到', '潮', '水', '濕', '了', ',', '就', '知'] ...
Top 3 ( 2%):['[CLS]', '等', '到', '潮', '水', '過', '了', ',', '就', '知'] ...
Top 4 ( 0%):['[CLS]', '等', '到', '潮', '水', '流', '了', ',', '就', '知'] ...
Top 5 ( 0%):['[CLS]', '等', '到', '潮', '水', '走', '了', ',', '就', '知'] ...
Top 6 ( 0%):['[CLS]', '等', '到', '潮', '水', '停', '了', ',', '就', '知'] ...
Top 7 ( 0%):['[CLS]', '等', '到', '潮', '水', '乾', '了', ',', '就', '知'] ...
Top 8 ( 0%):['[CLS]', '等', '到', '潮', '水', '到', '了', ',', '就', '知'] ...
Top 9 ( 0%):['[CLS]', '等', '到', '潮', '水', '溼', '了', ',', '就', '知'] ...
Top 10 ( 0%):['[CLS]', '等', '到', '潮', '水', '干', '了', ',', '就', '知'] ...4.4 通过BERT获取vocter向量
input_id = torch.tensor(tokenizer.encode("省哥豪哥66666")).unsqueeze(0)
print("分词映射后的id向量", input_id)
outputs = model(input_id)
print("输出词嵌入向量的形状", outputs)
print("词向量", outputs[0].size())
print("句向量", outputs[1].size())4.5 BERT下游的NLP任务
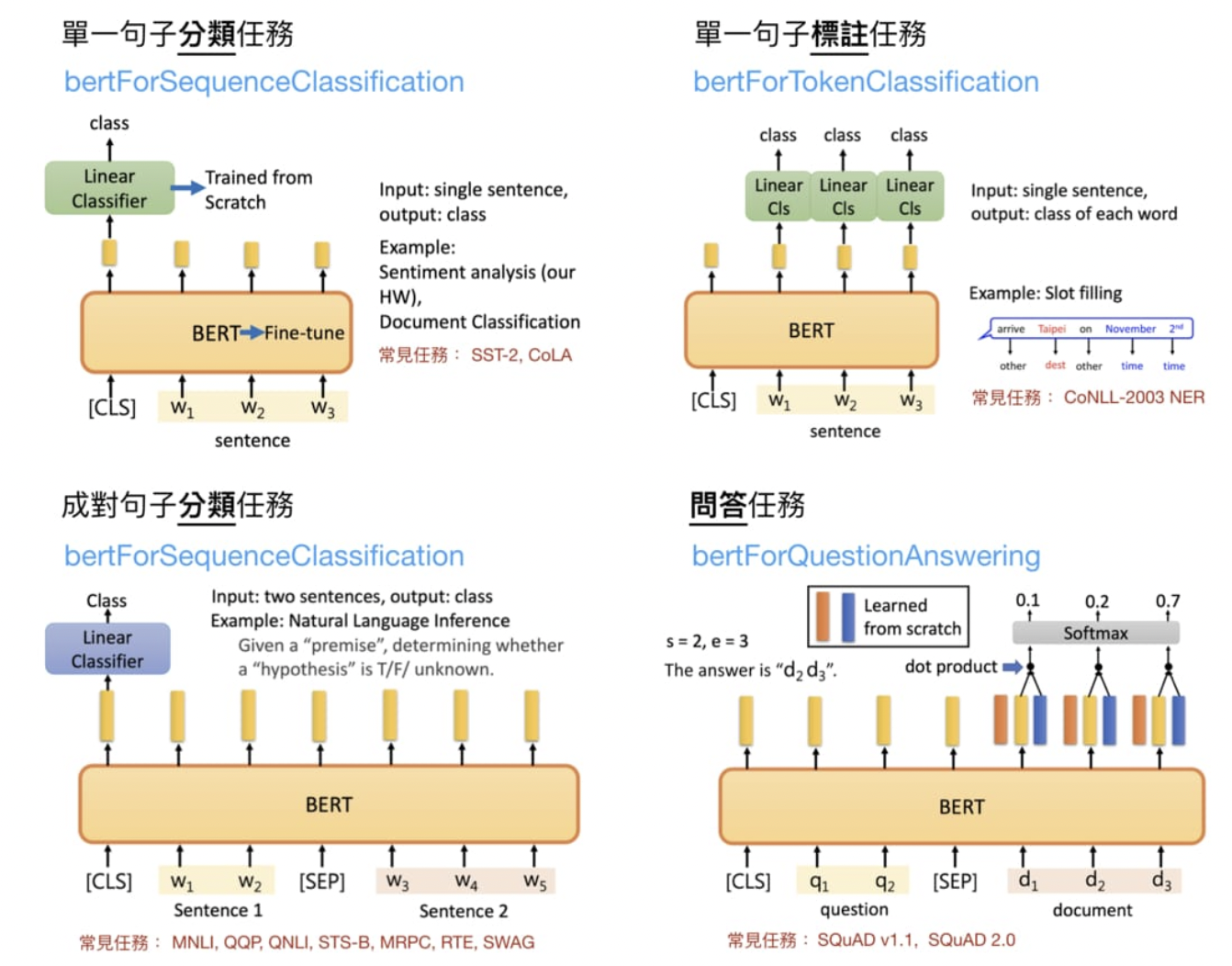
我们前面一直提到的 fine-tuning BERT 指的是在预训练后的 BERT 之上加入新的线性分类器(Linear Classifier),並利用下游任务的目標函式从头训练分类器並微调 BERT 的参数。这样做的目的是让整個模型(BERT + Linear Classifier)能一起最大化当前下游任务的目标。
# 載入一個可以做中文多分類任務的模型,n_class = 3
from transformers import BertForSequenceClassification
PRETRAINED_MODEL_NAME = "bert-base-chinese"
NUM_LABELS = 3
model = BertForSequenceClassification.from_pretrained(
PRETRAINED_MODEL_NAME, num_labels=NUM_LABELS)
clear_output()
# high-level 顯示此模型裡的 modules
print("""
name module
----------------------""")
for name, module in model.named_children():
if name == "bert":
for n, _ in module.named_children():
print(f"{name}:{n}")
else:
print("{:15} {}".format(name, module))输出
name module
----------------------
bert:embeddings
bert:encoder
bert:pooler
dropout Dropout(p=0.1, inplace=False)
classifier Linear(in_features=768, out_features=3, bias=True)5.BERT长文本处理方法
首选要明确一点, BERT预训练模型所接收的最大sequence长度是512.
那么对于长文本(文本长度超过512的句子), 就需要特殊的方式来构造训练样本. 核心就是如何进行截断.
- 1: head-only方式: 这是只保留长文本头部信息的截断方式, 具体为保存前510个token (要留两个位置给[CLS]和[SEP]).
- 2: tail-only方式: 这是只保留长文本尾部信息的截断方式, 具体为保存最后510个token (要留两个位置给[CLS]和[SEP]).
- 3: head+only方式: 选择前128个token和最后382个token (文本总长度在800以内), 或者前256个token和最后254个token (文本总长度大于800).



