TextCNN
Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。
1.模型原理
1.1 网络结构
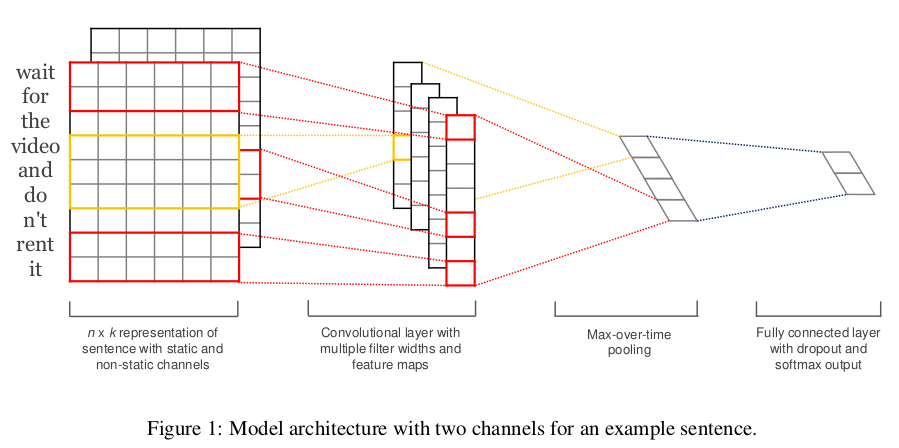
- TextCNN详细过程原理图如下
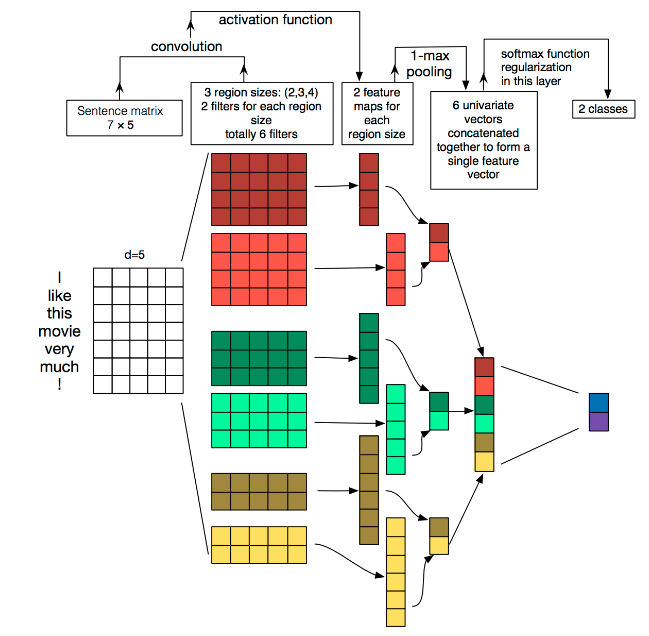
1.2 各组成模块
嵌入层(Embedding Layer)
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
通过一个隐藏层, 将 one-hot 编码的词投影到一个低维空间中,本质上是特征提取器,在指定维度中编码语义特征。 这样, 语义相近的词, 它们的欧氏距离或余弦距离也比较近。(作者使用的单词向量是预训练的,方法为fasttext得到的单词向量,当然也可以使用word2vec和GloVe方法训练得到的单词向量)。
卷积层(Convolution Layer)
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
在处理图像数据时,CNN使用的卷积核的宽度和高度的一样的,但是在text-CNN中,卷积核的宽度是与词向量的维度一致!这是因为我们输入的每一行向量代表一个词,在抽取特征的过程中,词做为文本的最小粒度。而高度和CNN一样,可以自行设置(通常取值2,3,4,5),高度就类似于n-gram了。由于我们的输入是一个句子,句子中相邻的词之间关联性很高,因此,当我们用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文(类似于skip-gram和CBOW模型的思想)。
池化层(Pooling Layer)
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
因为在卷积层过程中我们使用了不同高度的卷积核,使得我们通过卷积层后得到的向量维度会不一致,所以在池化层中,我们使用1-Max-pooling对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,而且认为这个最大值表示的是最重要的特征。当我们对所有特征向量进行1-Max-Pooling之后,还需要将每个值给拼接起来。得到池化层最终的特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
全连接层(connected layer)
最后接一层全连接的 softmax 层,输出每个类别的概率。
全连接层跟其他模型一样,假设有两层全连接层,第一层可以加上relu作为激活函数,第二层则使用softmax激活函数得到属于每个类的概率。
TextCNN的小变种
在词向量构造方面可以有以下不同的方式:
- CNN-rand: 随机初始化每个单词的词向量通过后续的训练去调整。
- CNN-static: 使用预先训练好的词向量,如word2vec训练出来的词向量,在训练过程中不再调整该词向量。
- CNN-non-static: 使用预先设置好的词向量,并在训练过程中进一步进行调整。
- CNN-multichannel:将static与non-static作为两通道的词向量。
参数与超参数
- sequence_length (Q: 对于CNN, 输入与输出都是固定的,可每个句子长短不一, 怎么处理? A: 需要做定长处理, 比如定为n, 超过的截断, 不足的补0. 注意补充的0对后面的结果没有影响,因为后面的max-pooling只会输出最大值,补零的项会被过滤掉)
- num_classes (多分类, 分为几类)
- vocabulary_size (语料库的词典大小, 记为|D|)
- embedding_size (将词向量的维度, 由原始的 |D| 降维到 embedding_size)
- filter_size_arr (多个不同size的filter)
2.文本预处理
2.1、读取数据集
2.2、将文字转换成数字特征
使用Tokenizer将文字转换成数字特征
使用Keras的Tokenizer模块实现转换。当我们创建了一个Tokenizer对象后,使用该对象的fit_on_texts()函数,可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小。使用word_index属性可以看到每次词对应的编码。
2.3、将每条文本转换为数字列表
将数据集中的每条文本转换为数字列表,使用每个词的编号进行编号
使用该对象的texts_to_sequences()函数,将每条文本转变成一个向量。
2.4、将每条文本设置为相同长度
使用pad_sequences()让每句数字影评长度相同
由于每句话的长度不唯一,需要将每句话的长度设置一个固定值。将超过固定值的部分截掉,不足的在最前面用0填充。
2.5、将每个词编码转换为词向量
使用Embedding层将每个词编码转换为词向量
Embedding层基于上文所得的词编码,对每个词进行one-hot编码,每个词都会是一个vocabulary_size维的向量;然后通过神经网络的训练迭代更新得到一个合适的权重矩阵(具体实现过程可以参考skip-gram模型),行大小为vocabulary_size,列大小为词向量的维度,将本来以one-hot编码的词向量映射到低维空间,得到低维词向量。需要声明一点的是Embedding层是作为模型的第一层,在训练模型的同时,得到该语料库的词向量。当然,也可以使用已经预训练好的词向量表示现有语料库中的词。
文本预处理目的:将每个样本转换为一个数字矩阵,矩阵的每一行表示一个词向量。
3. TextCNN代码实现
#构建TextCNN模型
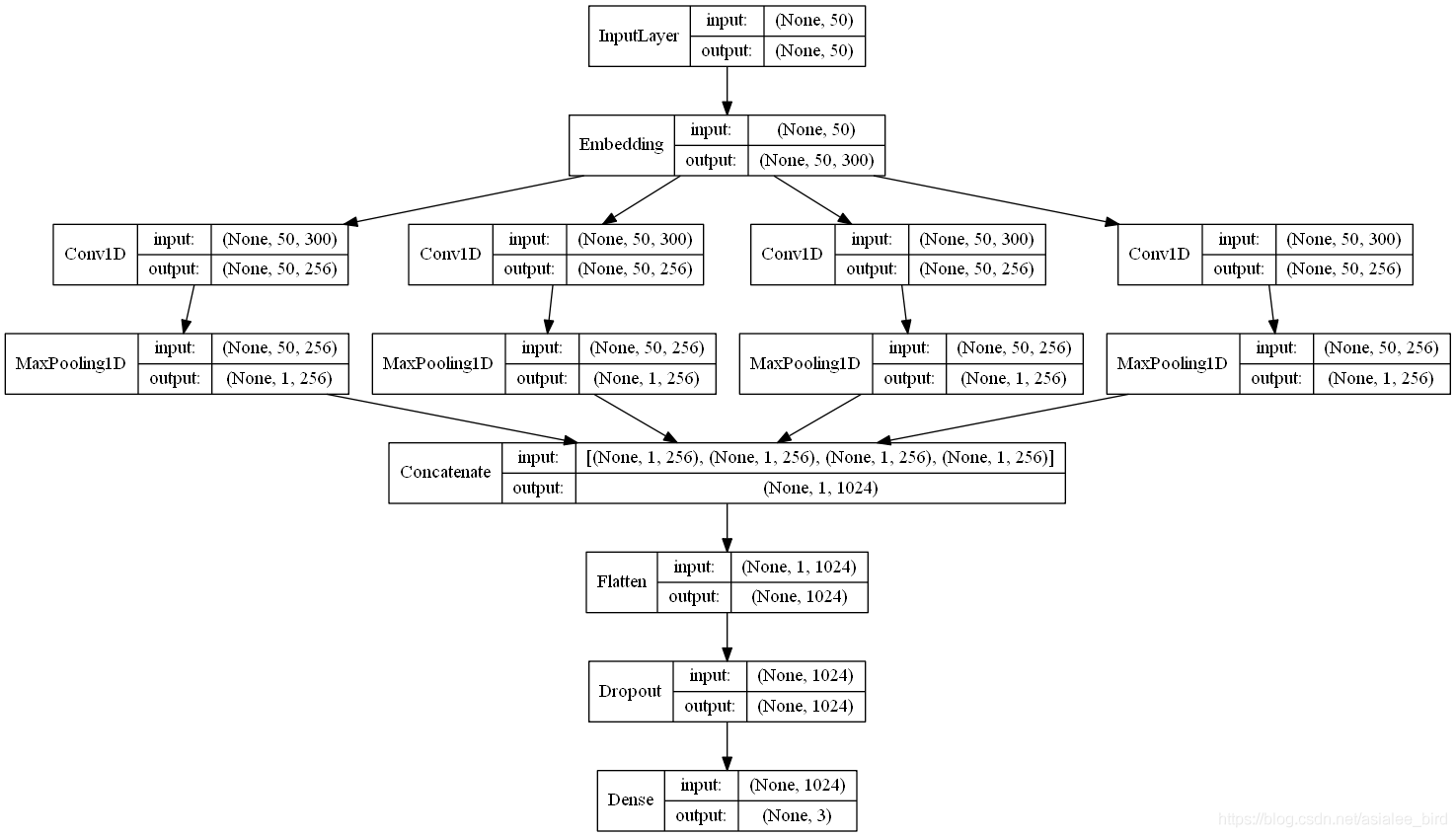
#模型结构:词嵌入-卷积池化*3-拼接-全连接-dropout-全连接
def TextCNN_model_1(x_train_padded_seqs,y_train,x_test_padded_seqs,y_test):
main_input = Input(shape=(50,), dtype='float64')
# 词嵌入(使用预训练的词向量)
embedder = Embedding(len(vocab) + 1, 300, input_length=50, trainable=False)
embed = embedder(main_input)
# 词窗大小分别为3,4,5
cnn1 = Conv1D(256, 3, padding='same', strides=1, activation='relu')(embed)
cnn1 = MaxPooling1D(pool_size=48)(cnn1)
cnn2 = Conv1D(256, 4, padding='same', strides=1, activation='relu')(embed)
cnn2 = MaxPooling1D(pool_size=47)(cnn2)
cnn3 = Conv1D(256, 5, padding='same', strides=1, activation='relu')(embed)
cnn3 = MaxPooling1D(pool_size=46)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(3, activation='softmax')(drop)
model = Model(inputs=main_input, outputs=main_output)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
one_hot_labels = keras.utils.to_categorical(y_train, num_classes=3) # 将标签转换为one-hot编码
model.fit(x_train_padded_seqs, one_hot_labels, batch_size=800, epochs=10)
#y_test_onehot = keras.utils.to_categorical(y_test, num_classes=3) # 将标签转换为one-hot编码
result = model.predict(x_test_padded_seqs) # 预测样本属于每个类别的概率
result_labels = np.argmax(result, axis=1) # 获得最大概率对应的标签
y_predict = list(map(str, result_labels))
print('准确率', metrics.accuracy_score(y_test, y_predict))
print('平均f1-score:', metrics.f1_score(y_test, y_predict, average='weighted'))


